






อธิบายสั้นๆ มันคือคู่แข่งของ Apache Hive ที่พัฒนาโดย Facebook ครับ
อธิบายแบบยาวๆ คือบริษัทแบบ Facebook ที่ต้องยุ่งเกี่ยวกับข้อมูลจำนวนมหาศาลระดับ petabyte มีงานเบื้องหลังที่ต้องดึงข้อมูลเก่าที่เก็บใน data warehouse (ที่เก็บด้วย Hadoop/HFS) มาวิเคราะห์อยู่บ่อยๆ ปัญหาคือระบบคิวรีข้อมูลอย่าง Hive ที่พัฒนาอยู่บนแนวคิด MapReduce นั้นออกแบบโดยเน้นสมรรถภาพโดยรวม (overall throughput) เป็นสำคัญ แต่สิ่งที่ Facebook ต้องการคือระบบคิวรีข้อมูลที่มีการตอบสนองรวดเร็ว (low query latency)
ในเมื่อในท้องตลาดไม่มีผลิตภัณฑ์ที่ต้องการก็สร้างมั นเองเสียเลย ผลออกมาเป็นโครงการชื่อ Presto ซึ่งเป็นเอนจินสำหรับคิวรีข้อมูลแบบ SQL (รองรับภาษา ANSI SQL ยังไม่ครบชุดแต่ก็เกือบทั้งหมด) มีจุดเด่นที่ความเร็วของการดึงข้อมูล
เนื่องจาก Presto ถูกออกแบบมาให้ดึงข้อมูลขนาดใหญ่ มันจึงต้องทำงานแบบกระจาย (distributed) เพียงแต่ใช้แนวคิดด้านการกระจายงานที่ต่างไปจาก MapReduce โดยใช้วิธีแบ่งงานเป็นขั้นๆ ตาม pipeline โดยออกแบบให้เหมาะสมกับสถาปัตยกรรมศูนย์ข้อมูลของ Facebook มาตั้งแต่ต้น (เพื่อลดการดึงข้อมูลข้ามเครือข่ายโดยไม่จำเป็น)
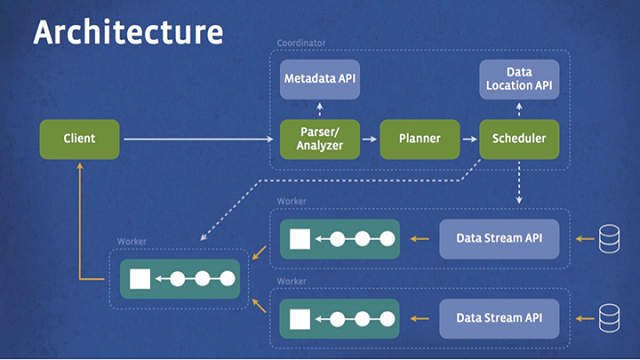
การทำงานของ Presto เป็นไปตามแผนภาพด้านล่าง เริ่มจากตัวไคลเอนต์ส่งคิวรีมายังตัว coordinator เพื่อแปลความของคิวรี และเตรียมเข้า scheduler คอยจัดคิวการรันคิวรีตาม pipeline ที่เหมาะสม แล้วส่งผลลัพธ์กลับไปยังไคลเอนต์ในท้ายที่สุด
Presto เขียนด้วยภาษา Java เพราะเข้ากับสถาปัตยกรรมของ Facebook ที่ส่วนใหญ่เป็น Java อยู่แล้ว โดยทีมงานก็บอกว่าตั้งใจปรับแต่งเพื่อลดปัญหาเรื่องห น่วยความจำและ garbage collection ของ Java มาเป็นอย่างดี ตัวซอฟต์แวร์ยังออกแบบมาให้มีส่วนต่อขยายกับฐานข้อมู ลชนิดอื่นๆ ที่ไม่ใช่ HDFS ได้ด้วย (เช่น ระบบ news feed อยู่บนระบบเฉพาะของบริษัทเอง)
ตอนนี้ Facebook เปิดซอร์สโค้ดของ Presto ภายใต้สัญญาอนุญาตแบบ Apache รายละเอียดของตัวโครงการดูได้จาก เว็บไซต์ของ Presto และ GitHub
ใครที่อยากได้ระบบคิวรีที่ผ่านงานระดับ 300 petabyte และใช้งานโดยพนักงาน Facebook กว่า 1,000 คน รวมถึงบริษัทดังๆ อย่าง Dropbox และ Airbnb ก็เข้าไปศึกษาข้อมูลเพิ่มเติมกันได้ครับ
ที่มา - Facebook Engineering
Facebook, SQL, Big Data, Open Source
อ่านต่อ...

 ตอบ-อ้างอิงข้อความ
ตอบ-อ้างอิงข้อความ
Bookmarks